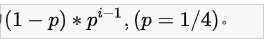心跳信息,消息头有一个16384/8的char数组,记录自己的槽信息,这是个bitmap 按位操作,1表示在。
心跳信息,消息体有被选中节点的信息,只是单个节点的信息。
所以整个ping消息的大小取决于myslots的大小而不是集群总节点的大小。16384正合适。
为什么Redis集群有16384个槽
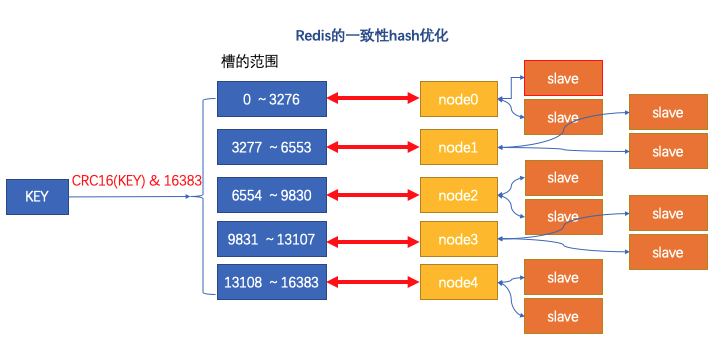
用槽的好处,就是扩容和容错特别好,个别分片有问题,影响范围小,很方便迁移,新增节点也容易,把部分的槽数据迁走就行了。
关键问题,为什么是16384呢?
The reason is:
Normal heartbeat packets carry the full configuration of a node, that can be replaced in an idempotent way with the old in order to update an old config. This means they contain the slots configuration for a node, in raw form, that uses 2k of space with16k slots, but would use a prohibitive 8k of space using 65k slots.
At the same time it is unlikely that Redis Cluster would scale to more than 1000 mater nodes because of other design tradeoffs.
So 16k was in the right range to ensure enough slots per master with a max of 1000 maters, but a small enough number to propagate the slot configuration as a raw bitmap easily. Note that in small clusters the bitmap would be hard to compress because when N is small the bitmap would have slots/N bits set that is a large percentage of bits set.
节点之间,定期会交换数据信息,发送心跳的ping/pong消息,这个涉及到消息的大小。
在redis节点发送心跳包时需要把所有的槽放到这个心跳包里,以便让节点知道当前集群信息,16384=16k,在发送心跳包时使用bitmap压缩后是2k(2 * 8 (8 bit) * 1024(1k) = 2K),也就是说使用2k的空间创建了16k的槽数。
虽然使用CRC16算法最多可以分配65535(2^16-1)个槽位,65535=65k,压缩后就是8k(8 * 8 (8 bit) * 1024(1k) = 8K),也就是说需要需要8k的心跳包,作者认为这样做不太值得;并且一般情况下一个redis集群不会有超过1000个master节点,所以16k的槽位是个比较合适的选择。
查看全部